SQL
- Introduction
- Relational Databases
- Thinking about database design
- Normalisation
- Types of SQL commands
- Links
- Setup practice workspace
- SQL Commands
- Curated Questions
- Video
Introduction
Structured Query Language. SQL is a domain-specific programming language used for managing and manipulating relational databases. SQL is designed to interact with databases by defining, querying, updating, and managing the data within them. - Univ. of CincinnatiRelational Databases
SQL commands are used to query relational databases -- a database that organizes data in tables, rows and columns. It is called a relational database because a table defines the relation between the columns (attributes).The table is an unordered set of rows.
A row(tuple) represents the relationship between its column (attribute) values for that row. It can also be thought of as an unordered set of attributes.
In the table, a row(tuple) is a particular data point in the vast universe of all the possible combinations of values that can exist on the table, across all the columns (attributes). In other words, the data in the table is the subset of all the allowed combinations of attributes values for the relation. Read more on relational algebra for more theoretical understanding.
Thinking about database design
Consider the following example -- You are assigned the task to store the following information for a highschool:- students data
- class data
- class teacher data
- subject and subject teacher data
- student grades for a subject data.
A rudimetary way of looking at all the requirements, one could simply store all the information in a single table against the student information. This table would have the following attributes:
Student_First Name, Student_Last Name, Student_DOB, Student_Address, Student_Phone Number, Student_Email, Class_ID, Class_Teacher_ID, Class_Teacher_Name, Subject_Name_1, Subject_Teacher_1, Student_Subject_Grade_1, Subject_Name_2, Subject_Teacher_2, Student_Subject_Grade_2, ...
The structure (schema) for the same would look like this:
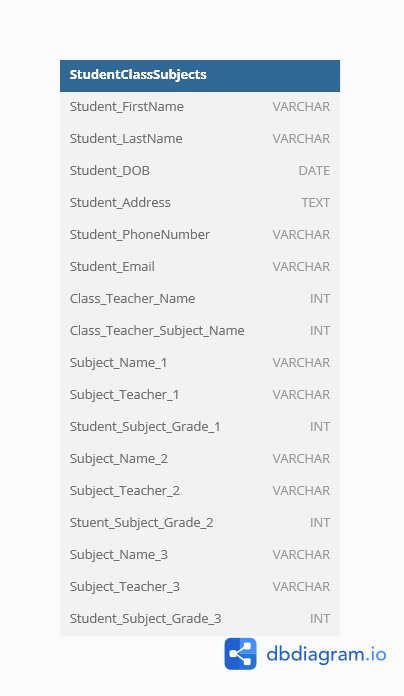
SQL Schema Code
Table StudentClassSubjectsTeachers {
Student_FirstName VARCHAR
Student_LastName VARCHAR
Student_DOB DATE
Student_Address TEXT
Student_PhoneNumber VARCHAR
Student_Email VARCHAR
Class_Teacher_Name INT
Subject_Name_1 VARCHAR
Subject_Teacher_1 VARCHAR
Student_Subject_Grade_1 INT
Subject_Name_2 VARCHAR
Subject_Teacher_2 VARCHAR
Stuent_Subject_Grade_2 INT
Subject_Name_3 VARCHAR
Subject_Teacher_3 VARCHAR
Student_Subject_Grade_3 INT
}
Need for Keys
There is a catch though. Every kid is unique, not just in a rhetoric way, but for the sake of searching through our table too. To pinpoint a particular student and their details, a combination of First Name, Last Name, Address, Phone Number, and, Email ID needs to be considered. This is similar to seeking {Ved, Gupta, Mumbai, 91XXXX, ved@abc.com} whenever you want to query for a particular student.
This way, a simple search like "Who is the class teacher of the student" turns into "Who is the class teacher of Ved, Gupta, Mumbai, 91XXXX, ved@abc.com". We need a way that helps us concisely pinpoint a student in this table.
Introducing a new column(attribute) like Student_ID does just that, with brevity. It is a numerical identifier that is unique to every student in the table. This would help simplify our query to just "Who is the class teacher of the student with Student_ID 20240001".
Definition: A primary key for a table is defined as the minimum set of attributes that could be used to uniquely identify a row(tuple) in the table.
For instance, without the Student_ID, we were earlier looking against the set of attributes {Ved, Gupta, Mumbai, 91XXXX, ved@abc.com}. With the definition of Student_ID in the table structure (schema) it becomes a lot easier to search for a particular row in the table and fetch data from its rows. Student_ID is now the Primary Key for this students table.
Learn more about types of keys here
Querying against other information
Note that this data is very centric around students. It's super efficient for querying information against particular student. Thus information like these would be fetched instantly from the rows:
- "What subjects does the student study"
- "Who is the class teacher of the student"
- "Who teaches SUBJECT_Name_3 to the student"
- "What is the student's contact number"
What is the issue here? Even though all the information is in the same table. How is searching for students's info better for the table than for a teacher?
It's the table structure. Every row representing a student. There is no redundancy of students scattered across the data. However the teachers and classes are spread across the entire table. And thus, we have to take a look at ALL the places teachers are mentioned. What if we create an identifier for every teacher and class here?
The issue of redundancies
Note that there are a lot of information redundancies in the table:
- A student from (say) class
Normalisation
Normalisation of tables is the process of making the data less redundant which increases data consistency and helps avoid update anomalies. Normalization seems intimidating at first but going through some examples we'll realise that it's more intuitive to do once we skip past the intimidating jargon.Types of SQL commands
Data Definition Language(DDL): SQL commands used to create, modify, and delete database structures such as tables, indexes, and views.Data Manipulation Language (DML): SQL commands used to insert, update, and delete data within a database.
Links
Learn- MySQL Tutorial
- 20 Important Queries
- AnimateSQL -- Learn how SQL commands work through animations
- B+ Tree Visualisation
- dbdiagram.io -- Generate schema diagrams
Setup practice workspace
A basic working SQL server using docker- $ docker pull mysql
- $ docker create network work
- $ docker run --name testmysql --network work -e MYSQL_ROOT_PASSWORD=password -d mysql:latest
- $ docker run -it --network work --rm mysql mysql -htestmysql -uroot -p
- #(Enter 'password' as your password)
SQL Commands
- show databases;
- create database test;
- use test;
- create table t ( col1 char , col2 int);
- insert into t values ('a',1),('b',2);
- SELECT * from t;
- select col1 from t WHERE col2 = 1;
- select col2 from t where col1 LIKE 'a%';
- select distinct city FROM station WHERE city REGEXP "^[aeiou].*";
AGGREGATION
- MIN, MAX, COUNT, AVG
- select col1 , count(col1) from t group by col1;
- select t1.col1 , t2.col1 from t1 INNER JOIN t2 ON t1.col2 = t2.col2;
- select t1.col1 , t2.col1 from t1 LEFT JOIN t2 ON t1.col2 = t2.col2;
- select t1.col1 , t2.col1 from t1 RIGHT JOIN t2 ON t1.col2 = t2.col2;
UNION ALL => DUPLICATES allowed
- select * from t1 UNION select * from t2;
Curated Questions
1. Query even ID numbers in table STATION.
select * from station where MOD(id,2)=0;
2. Query to find the difference between the total number of cities and the unique number of cities in the table STATION.
select count(city)-count(distinct city) from station;
3. Query city with the longest name from table STATION
select city from station orderby length(city) desc, city limit 1;
4. Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Result cannot contain duplicates.
select distinct city FROM station WHERE city REGEXP "^[aeiou].*";
5. Query elements from A(a,b,c) which are not in table B(a,c,d)
select A.* LEFT JOIN B ON A.column = B.column WHERE B.column IS NULL;